4 Core Functions
4.1 Setup Testing Data
Define a toy example to use in development:
## correspondence/concordance table
codes_BA <- dplyr::tribble(~ std_B, ~ std_A,
"A1", "x1111", # one-to-one
"B2", "x2222", # many-to-one
"B2", "x3333",
"C3", "x4444", # one-to-many (4)
"C4", "x4444",
"C4", "x6666", # many-to-many
"C5", "x4444",
"C6", "x4444",
"C7", "x5555", # one-to-many (3)
"C8", "x5555",
)
## panel_map
weights_BA <- codes_BA |>
dplyr::distinct(std_B, std_A) |>
dplyr::group_by(std_A) |>
dplyr::mutate(n_dest = dplyr::n(),
weight = 1 / n_dest) |>
dplyr::ungroup()
pm_BA <- weights_BA |>
dplyr::select(std_B, std_A, weight)Write this data into an internal list for testing purposes.
equal_pm <- list("codes_BA" = codes_BA,
"weights_BA" = weights_BA,
"pm_BA" = pm_BA)We can visualise a panel map as the addition of weights to the concordance:
library(ggplot2)
inc_long <- tidyr::expand(codes_BA, std_A, std_B) |>
dplyr::left_join(pm_BA, by = c("std_A", "std_B")) |>
dplyr::transmute(to = std_B, from = std_A, weight = weight)
gg_inc_mtx <- inc_long |>
plt_inc_long_mtx(to, from, weight) +
ggtitle("Concordance as Incidence Matrix")
gg_pm_mtx <- gg_inc_mtx +
geom_text(data = dplyr::filter(inc_long, !is.na(weight)), aes(label=round(weight, 2))) +
ggtitle("adding equal weights for Valid Panel Map")gg_inc_mtx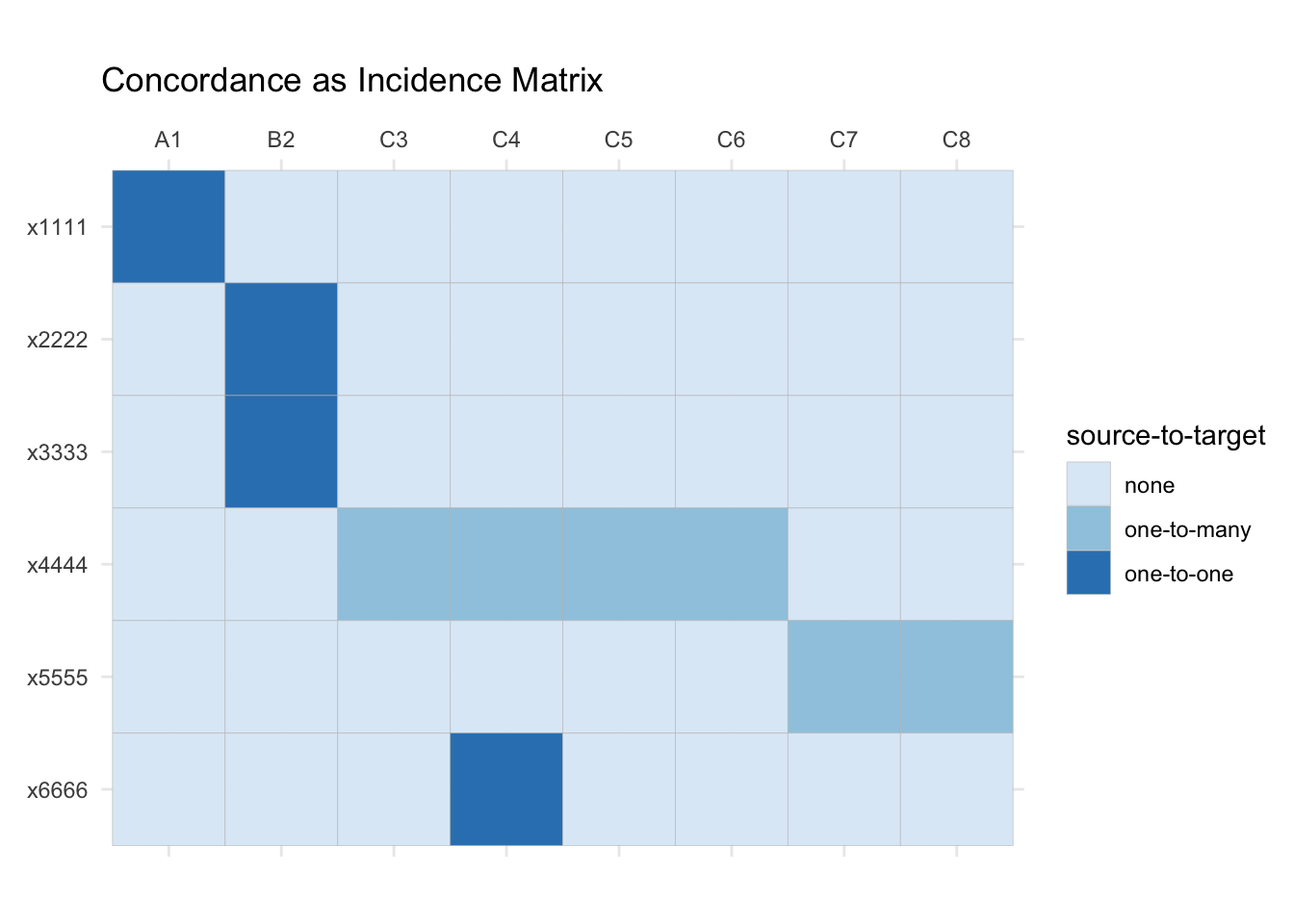
gg_pm_mtx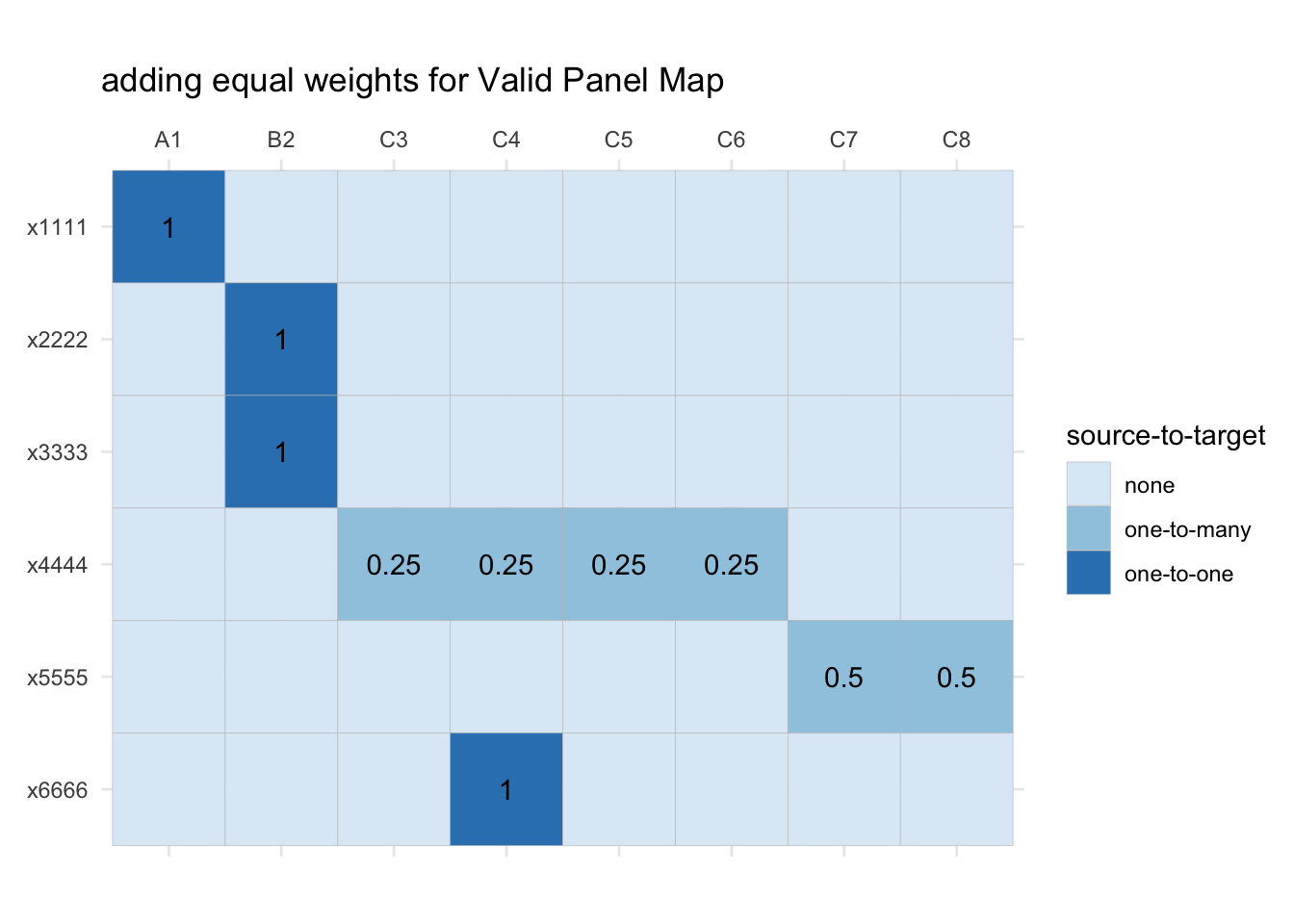
4.2 Valid Transformation Conditions
4.2.1 Complete Mapping Weights
A valid panel map is an mapping from source to target nomenclatures which when applied to suitably dimensioned source data, transforms that data into the target nomenclature without creation or loss of value (beyond floating point rounding). This can also be thought of as a condition whereby the sum total of a variable remains the same before and after the transformation.
The following condition is necessary and sufficient for a set of Source Codes, Target Codes and Mapping Weights to be a valid panel map:
The sum of all Mapping Weights associated with any given Source Code totals to 1
To demonstrate, let us generate some source data:
## generate some data
set.seed(1832)
std_A_codes <- unique(codes_BA$std_A)
(data_A <-
dplyr::tibble(std_A = std_A_codes,
A_100 = 100,
A_prod = round(abs(rnorm(length(std_A_codes)) * 10000),2)
)
)## # A tibble: 6 × 3
## std_A A_100 A_prod
## <chr> <dbl> <dbl>
## 1 x1111 100 15275.
## 2 x2222 100 7432.
## 3 x3333 100 1970.
## 4 x4444 100 837.
## 5 x6666 100 9976.
## 6 x5555 100 1217.Create more testing data.
equal_pm$data_A <- data_A |>
dplyr::select(std_A, A_100)Now let’s switch to using the matrix representation of panel maps:
Let \(\bf{C}\) be a \(n \times m\) matrix showing the incidence between two disjoint sets (inc_mtx), and let \(\bf{X}\) be the source variables (x_mtx) requiring transformation. Then, the transformed data is \(\bf{Z} = \bf{C'X}\):
## incidence matrix
inc_mtx <- inc_long |>
tidyr::replace_na(list(weight=0)) |>
inc_long_to_mtx(to, weight)
## source data matrix
x_mtx <- as.matrix(data_A[,-1])
dimnames(x_mtx)[[1]] <- std_A_codes
## transformed data
z_mtx <- t(inc_mtx) %*% x_mtxround(t(inc_mtx), 2)## x1111 x2222 x3333 x4444 x5555 x6666
## A1 1 0 0 0.00 0.0 0
## B2 0 1 1 0.00 0.0 0
## C3 0 0 0 0.25 0.0 0
## C4 0 0 0 0.25 0.0 1
## C5 0 0 0 0.25 0.0 0
## C6 0 0 0 0.25 0.0 0
## C7 0 0 0 0.00 0.5 0
## C8 0 0 0 0.00 0.5 0print(x_mtx)## A_100 A_prod
## x1111 100 15274.93
## x2222 100 7431.98
## x3333 100 1970.36
## x4444 100 836.72
## x6666 100 9976.27
## x5555 100 1216.67print(z_mtx)## A_100 A_prod
## A1 100 15274.930
## B2 200 9402.340
## C3 25 209.180
## C4 125 1425.850
## C5 25 209.180
## C6 25 209.180
## C7 50 4988.135
## C8 50 4988.135Notice that the sum total of A_100 is the same before and after the transformation.
colSums(x_mtx)## A_100 A_prod
## 600.00 36706.93colSums(z_mtx)## A_100 A_prod
## 600.00 36706.93Now, let’s edit the panel map such that the weights no longer sum to one:
## edit weights
bad_pm <- pm_BA |>
dplyr::mutate(weight = dplyr::case_when(
weight == 1 ~ weight,
weight < 0.5 ~ weight - 0.03,
weight >= 0.5 ~ weight + 0.01,
T ~ weight))
## incidence matrix
bad_mtx <- bad_pm |>
inc_long_to_mtx(std_B, weight)
bad_mtx[is.na(bad_mtx)] <- 0
## transform data badly
bad_z <- t(bad_mtx) %*% x_mtxNotice what happens when we apply the transformation:
round(t(bad_mtx), 2)## x1111 x2222 x3333 x4444 x6666 x5555
## A1 1 0 0 0.00 0 0.00
## B2 0 1 1 0.00 0 0.00
## C3 0 0 0 0.22 0 0.00
## C4 0 0 0 0.22 1 0.00
## C5 0 0 0 0.22 0 0.00
## C6 0 0 0 0.22 0 0.00
## C7 0 0 0 0.00 0 0.51
## C8 0 0 0 0.00 0 0.51print(x_mtx)## A_100 A_prod
## x1111 100 15274.93
## x2222 100 7431.98
## x3333 100 1970.36
## x4444 100 836.72
## x6666 100 9976.27
## x5555 100 1216.67print(bad_z)## A_100 A_prod
## A1 100 15274.9300
## B2 200 9402.3400
## C3 22 184.0784
## C4 122 10160.3484
## C5 22 184.0784
## C6 22 184.0784
## C7 51 620.5017
## C8 51 620.5017Notice that the sum totals are no longer the same before and after the transformation:
colSums(x_mtx)## A_100 A_prod
## 600.00 36706.93colSums(bad_z)## A_100 A_prod
## 590.00 36630.86Hence, the validity condition can also be expressed as follows: > A given incidence matrix \(\bf{K}\) with dimensions \(n \times m\) is a valid panel map if and only if \(\bf{K}\boldsymbol{1} = \boldsymbol{1}\) where \(\boldsymbol{1}\) is a unit vector of length \(m\):
ones <- rep_len(1, ncol(inc_mtx))round(inc_mtx, 2)## A1 B2 C3 C4 C5 C6 C7 C8
## x1111 1 0 0.00 0.00 0.00 0.00 0.0 0.0
## x2222 0 1 0.00 0.00 0.00 0.00 0.0 0.0
## x3333 0 1 0.00 0.00 0.00 0.00 0.0 0.0
## x4444 0 0 0.25 0.25 0.25 0.25 0.0 0.0
## x5555 0 0 0.00 0.00 0.00 0.00 0.5 0.5
## x6666 0 0 0.00 1.00 0.00 0.00 0.0 0.0inc_mtx %*% ones## [,1]
## x1111 1
## x2222 1
## x3333 1
## x4444 1
## x5555 1
## x6666 14.2.1.1 Functions
Internal switching function for flow control and error messages
#' Flag Bad Mapping Weights
#'
has_bad_weights <- function(df, code_in, code_out, weights){
bad_rows <- df |>
dplyr::group_by({{code_in}}) |>
dplyr::summarise(total = sum({{weights}}),
weights = paste({{weights}}, collapse=",")) |>
dplyr::filter(total != 1)
is_bad <- !(nrow(bad_rows) == 0)
result <- list(fail = is_bad,
table = bad_rows)
return(result)
}This function checks if the panel map has valid weights and returns the panel map if it does. It can be used to validate a panel map after editing or modifications. For example:
## prepare panel map
new_pm <- old_pm |>
mutate() |>
filter() |>
check_pm_weights(code_in, code_out, weights)#' Check panel map weights are valid
#'
#' Checks if `code_in`, `code_out` and `weights` columns of data frame forms a valid panel map.
#'
#' @param df Data Frame containing weighted links `weights` between `code_in` and `code_out`.
#' @param code_in Variable in `code_dict` containing source codes to convert from.
#' @param code_out Variable in `code_dict` containing destination codes to convert to.
#' @param weights Column containing weights for transforming values from `code_in` to `code_out`
#'
#' @exports
#'
#' @returns The original data frame if the check is passed and an error if not.
check_weights <- function(df, code_in, code_out, weights){
has_result <- has_bad_weights(df, {{code_in}}, {{code_out}}, {{weights}})
if (has_result$fail){
cli::cli_abort(c(
"{.var weights} for each {.var code_in} must sum to 1",
""
),
class="invalid_weights"
)
} else {
return(df)
}
}4.2.1.2 Tests
- flag function returns expected output
- check function works as expected:
- returns informative error message
- returns unchanged panel map
Add testing data
equal_pm$bad_weights <- equal_pm$pm_BA |>
dplyr::mutate(weight = dplyr::case_when(
weight == 1 ~ weight,
weight < 0.5 ~ weight - 0.03,
weight >= 0.5 ~ weight + 0.01,
T ~ weight))Write tests:
testthat::test_that(
"has_bad_weights() returns correct flags",
{
# good weights
testthat::expect_false(
has_bad_weights(equal_pm$pm_BA, std_A, std_B, weight)$fail
)
# bad weights
testthat::expect_true(
has_bad_weights(equal_pm$bad_weights, std_A, std_B, weight)$fail
)
}
)
testthat::test_that(
"check_weights() works as expected",
{
# good weights
testthat::expect_identical(
check_weights(equal_pm$pm_BA, std_A, std_B, weight), equal_pm$pm_BA)
# bad weights
testthat::expect_error(
check_weights(equal_pm$bad_weights, std_A, std_B, weight),
class="invalid_weights"
)
}
)## Test passed 🎉## Test passed 😀4.2.2 No Missing Data Values
Except for a one-to-one transfer between classifications, there is no way for NA values in the Source Data to be preserved when transformed into the Target Classification. It doesn’t make sense to split NA into smaller parts, or to aggregate NA into a sum.
Hence, any missing values need to be explicitly dealt with before applying a Panel Map transformation. Exactly how missing values should be treated will vary from dataset to dataset. This could involve replace the missing values with zeroes or some imputed values, or to remove them completely.
pm_BA |>
plt_pm_sigmoid(from=std_A, to=std_B, weights = weight) +
scale_fill_brewer(palette="RdPu", direction=-1)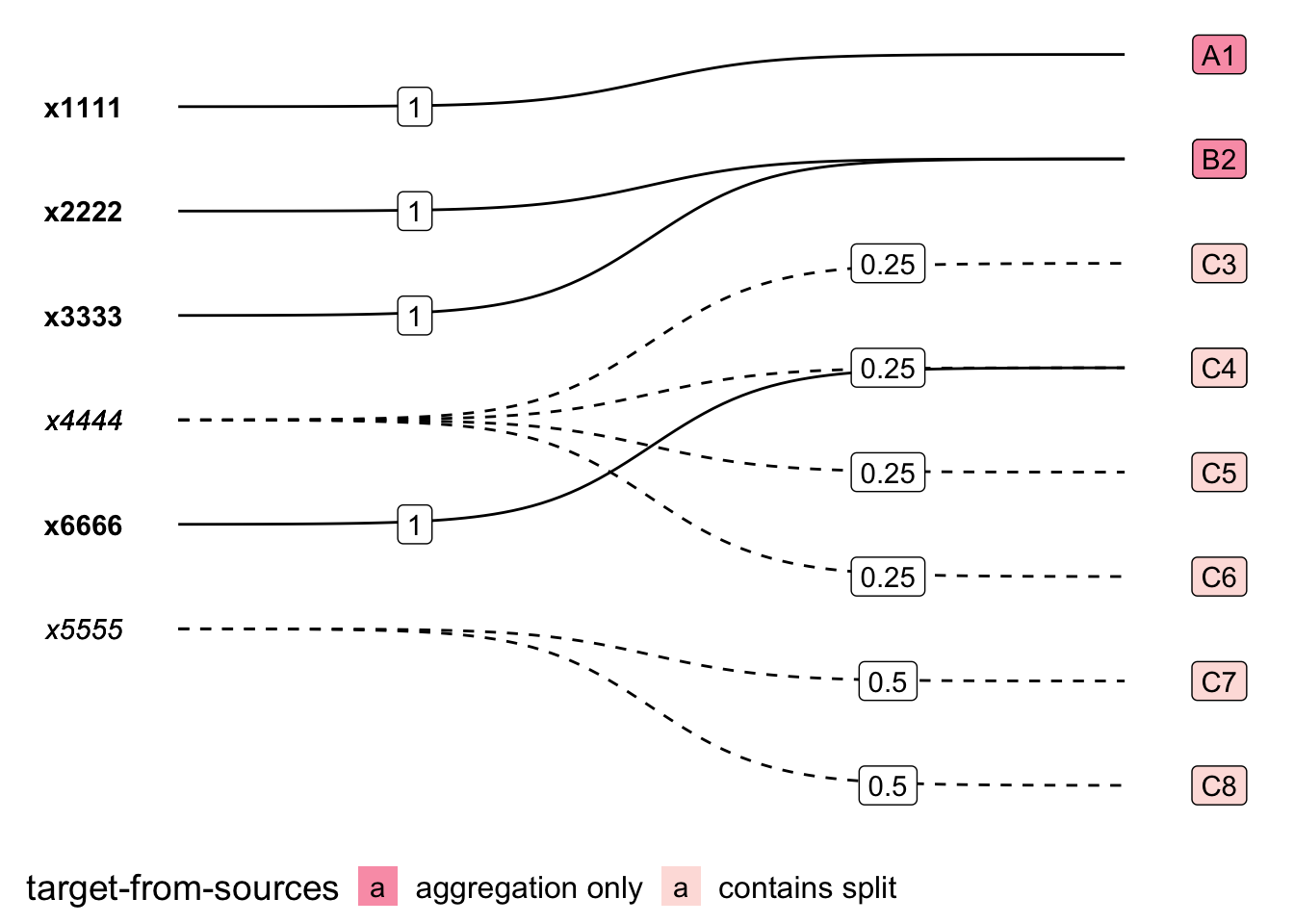
4.2.2.1 Functions
This function flags if the variables you want to transform have any missing values.
#' Flags NA in Source Data
#'
has_missing <- function(.data){
is_miss <- .data |>
anyNA()
result <- list(fail=is_miss)
return(result)
}This function checks the dataframe for missing values, and returns the original dataframe or tells the user to fix the NAs in their data. The dataframe should already be subsetted to contain only the Source Code and Source Value columns:
## prepare data for transformation
data_in <- all_df |>
select(code_in, x1, x2) |>
check_missing()#' Checks Source Data for Missing Values
#'
#' @inheritParams concord
#'
#' @export
check_missing <- function(data_in){
has_result <- has_missing(data_in)
if(has_result$fail){
cli::cli_abort(
"{.var data_in} should not have any NA",
class="vals_na"
)
} else {
return(data_in)
}
}4.2.2.2 Tests
Feed in data with missing values and expect: - TRUE flag - Error message
Add testing data
equal_pm$bad_data <- equal_pm$data_A
equal_pm$bad_data[1, 2] <- NAtestthat::test_that(
"has_missing() returns expected flags",
{
# good weights
testthat::expect_false(
has_missing(equal_pm$data_A)$fail
)
# bad weights
testthat::expect_true(
has_missing(equal_pm$bad_data)$fail
)
}
)
testthat::test_that(
"check_missing() works as expected",
{
## good data
testthat::expect_identical(check_missing(equal_pm$data_A), equal_pm$data_A)
## bad data
testthat::expect_error(check_missing(equal_pm$bad_data),
class = "vals_na")
}
)## Test passed 🥇## Test passed 🌈4.2.3 Source Code Coverage
A Panel Map must cover all Source Codes present in the Source Data. In other words, for a transformation to be valid, no Source Data should be left behind.
gg_x_mtx <- plt_df_mtx(data_A, A_100:A_prod, std_A)
library(patchwork)
gg_pm_mtx +
guides(fill="none") +
ggtitle("") + gg_x_mtx +
scale_y_discrete(position="right", limits=rev) +
patchwork::plot_annotation(title="Panel Map covers Source Data")##
## Attaching package: 'patchwork'## The following object is masked from 'package:cowplot':
##
## align_plots## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.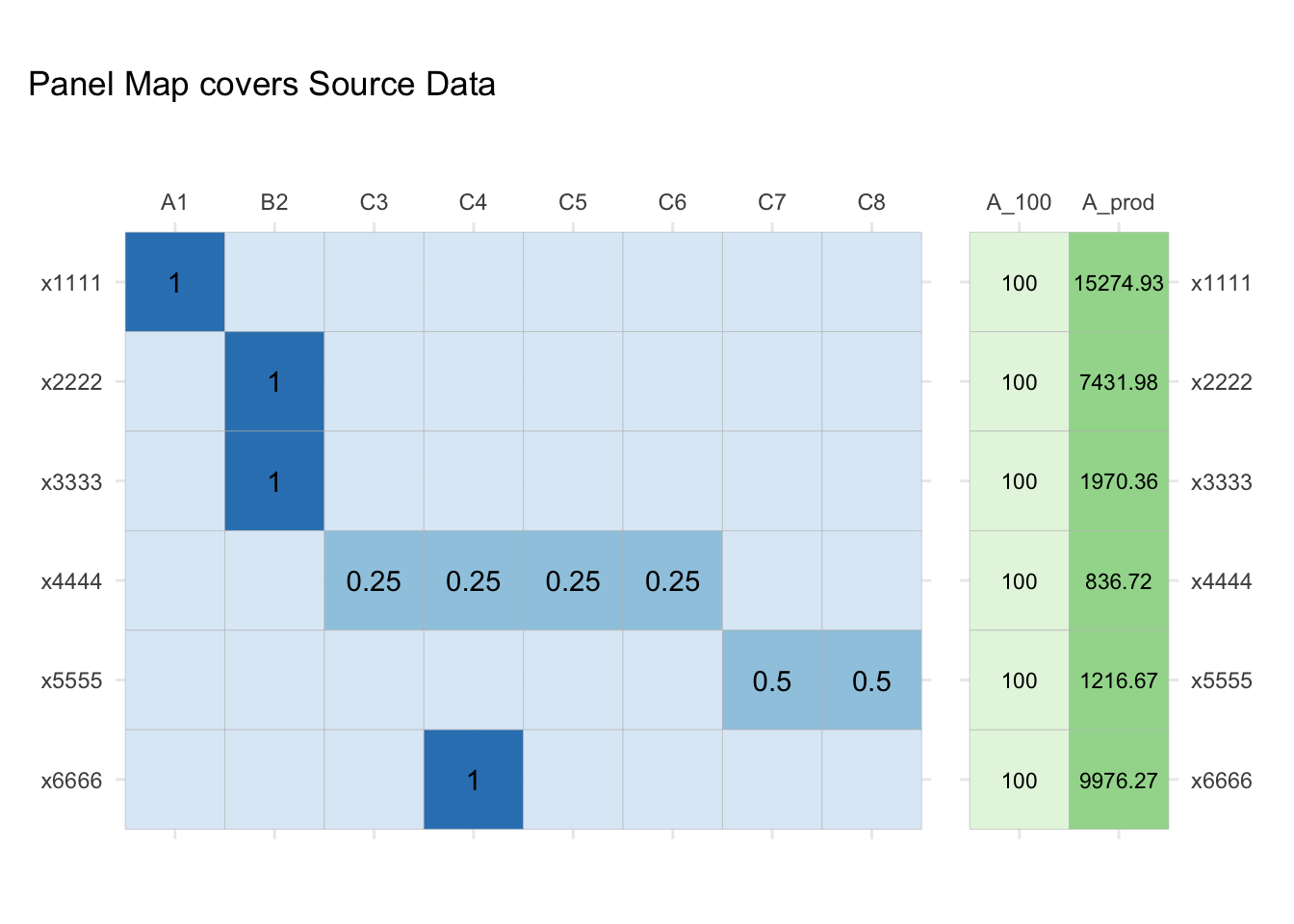
gg_x_bad <- data_A |>
dplyr::add_row(std_A = "x7285!",
A_100 = 100,
A_prod = 3895.3) |>
plt_df_mtx(A_100:A_prod, std_A)
gg_pm_bad <- tidyr::expand_grid(from=c(NA), to=unique(codes_BA$std_B)) |>
dplyr::mutate(weight=NA) |>
bind_rows(inc_long) |>
plt_inc_long_mtx(to, from, weight) +
geom_text(data = dplyr::filter(inc_long, !is.na(weight)), aes(label=round(weight, 2)))
library(patchwork)
gg_pm_bad +
guides(fill="none") +
ggtitle("") +
gg_x_bad +
scale_y_discrete(position="right", limits=rev) +
scale_fill_brewer(palette="Purples") +
patchwork::plot_annotation(title="Panel Map does not cover fully Source Data")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.## Scale for 'fill' is already present. Adding another scale for 'fill', which
## will replace the existing scale.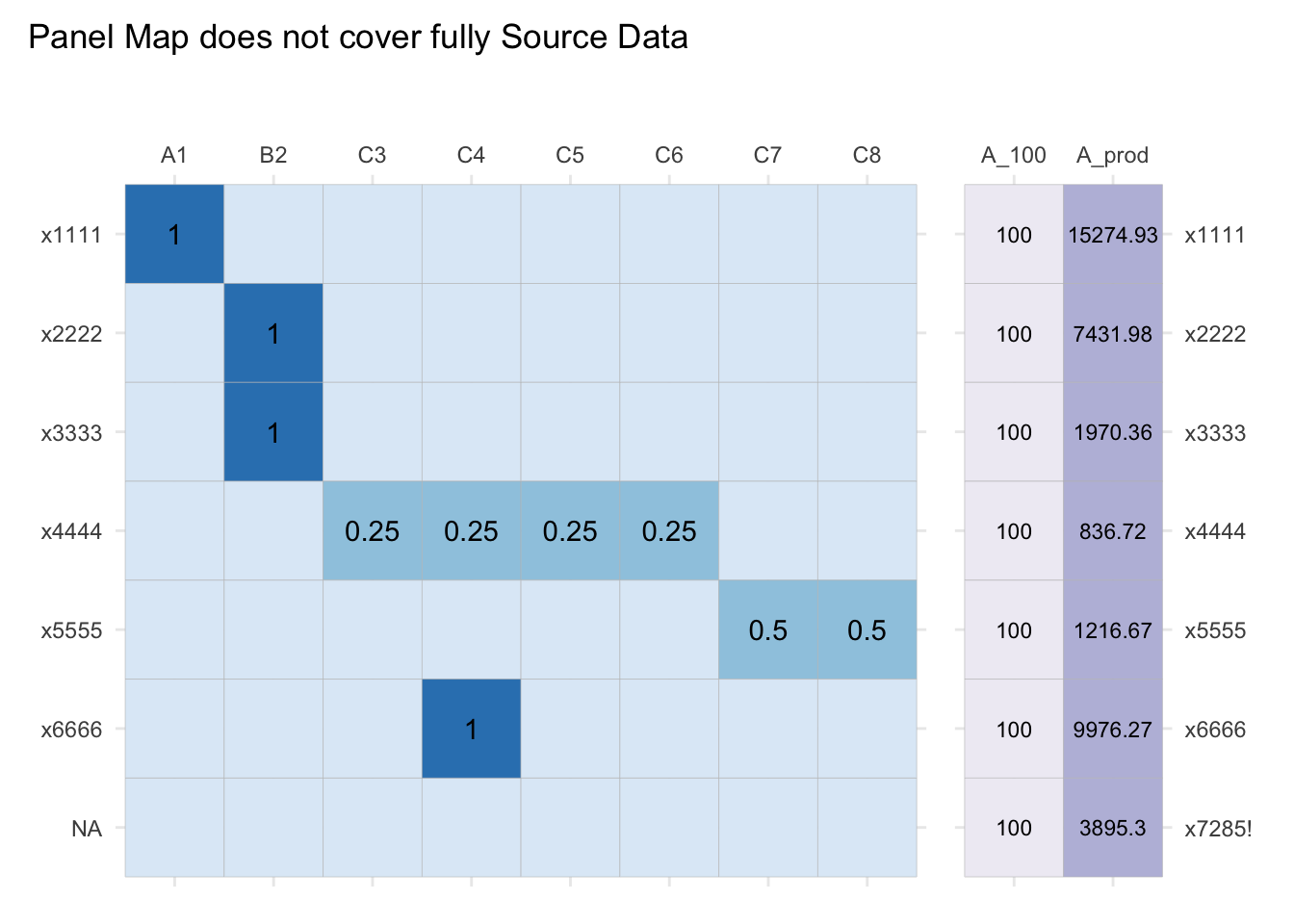
Depending on how the transformation is implemented, coverage mismatches can result in both explicit and implicit/hidden errors. In particular, having conformable matrix dimensions is not sufficient to avoid corrupting data unless you check that the indices match. This is a common issue with using matrices for data wrangling, so this package implements transformations using database operations.
4.2.3.1 Functions
Internal checking function – assumes .map is a valid map. Note this could be (quickly) checked for using a class condition discussed in GitHub issue #43
#' Flag if data set is not completely cover by panel map
#'
#' @inheritParams use_panel_map
#'
has_coverage <- function(.data, .map, .from){
missing_links <- .data |>
dplyr::select(tidyselect::all_of(.from)) |>
dplyr::distinct() |>
dplyr::anti_join(.map, by = .from)
is_covered <- (nrow(missing_links) == 0)
results <- list(fail=!is_covered,
table=missing_links)
return(results)
}Error constructing function, also used in concord()
#' Check coverage of panel map over source data
#'
#' @inheritParams concord
#' @inheritParams use_panel_map
#'
#' @returns `data_in` if check is successful, throws error otherwise.
#' @examples
#'
#' /notrun{
#' check_coverage(df, pm, "std_A")
#' }
#'
#'
check_coverage <- function(data_in, pm, .from){
# call flag function
has_result <- has_coverage(data_in, pm, .from)
# conditionals
if(has_result$fail){
cli::cli_abort(
"{.var data_in$from_code} has values not covered by {.var pm$from_code}",
class="not_covered"
)
} else {
return(data_in)
}
}4.2.3.2 Tests
Add some more testing data
equal_pm$data_extra <- equal_pm$data_A |>
dplyr::add_row(std_A = "x7777", A_100 = 100)testthat::test_that(
"has_coverage() returns expected flags",
{
## complete coverage
testthat::expect_false(has_coverage(equal_pm$data_A, equal_pm$pm_BA, "std_A")$fail)
## incomplete coverage
testthat::expect_true(has_coverage(equal_pm$data_extra, equal_pm$pm_BA, "std_A")$fail)
}
)## Test passed 🥇testthat::test_that(
"check_coverage() works as expected",
{
## complete coverage
testthat::expect_identical(check_coverage(equal_pm$data_A, equal_pm$pm_BA, "std_A"), equal_pm$data_A)
## incomplete coverage
testthat::expect_error(check_coverage(equal_pm$data_extra, equal_pm$pm_BA, "std_A"),
class = "not_covered")
}
)## Test passed 🥳4.3 Use Panel Map on Data
4.3.1 Single Step Concordance
4.3.1.1 Stylized Code
Assuming all the validity conditions are met, we want a simple and concise way to apply a panel map to data which looks something like:
# --- prepare panel map --------------------
df_pm <- read_csv("concordance-table.csv") |>
conformr::make_panel_map_equal(...) |>
conformr::validate_panel_map(...)
# --- prepare data ---------------------------
df_data_in <-
read_csv("your-source-data.csv") |>
conformr::validate_data_in(...)
## --- apply (valid) transformation -----------
conformr::concord(
data_in = df_data_in, pm = df_pm,
from_code = source, to_code = target,
m_weights = weight, values_from = value_in,
.suffix = "_out"
)Preparing a panel map and data for valid transformation could look like:
## --- prepare panel map -------------------- ##
# by importing a manually encoded map
df_pm <- read_csv("your-panel-map.csv")
# or creating one from a concordance table
df_pm <- read_csv("concordance-table.csv") |>
conformr::make_panel_map_equal(
code_in = source, code_out = target,
.weights_to = "weight")
## --- prepare source data ------------------ ##
# example using {dplyr}:
df_data_in <-
read_csv("your-source-data.csv") |>
drop_na() |>
group_by(source) |>
summarise(value_in = sum(gdp))
## --- apply (valid) transformation --------- ##
conformr::concord(
data_in = df_data_in, pm = df_pm,
from_code = source, to_code = target,
m_weights = weight, values_from = value_in,
.suffix = "_out"
)4.3.1.2 Warnings and Errors
The concordance function should throw error when:
- panel map (
pm) has invalid weights - source data (
data_in) column has missing values
The concordance function should warn users about data prep?:
- multiple rows for a given
code_inindata_in; should only have one set ofvalue_infor eachcode_in
4.3.1.3 Functions
This function takes a valid panel map and data with matching names for the Source Code columns and transforms the data to the Target Classification.
Add informative error messages later:
in_data_in <- (str.vals %in% colnames(data_in))
if (!all(in_data_in)){
cli::cli_abort(
"{.code {names(dots)[!in_data_in]}} cannot be found in {.var data_in}",
class = "cols_not_found")
}#' Transform data from Source to Target classification using Panel Map
#'
#' Currently checks for valid Mapping weights, missing values, and coverage.
#'
#' @param data_in A Data Frame containing the values you want to transform
#' @param pm A Data Frame containing valid Mapping Weights between `from_code` and `to_code`.
#' @param from_code Variable containing Source Codes. Must be present in both `data_in` and `pm`
#' @param to_code Variable in `pm` containing Target Codes.
#' @param m_weights Variable in `pm` containing Mapping Weights.
#' @param values_from A vector of variables in `data_in` to be transformed. E.g. `c(var1, var2)`
#' @param .suffix An (optional) string appended to each `values_from` name to create column names for transformed values.
#' Defaults to `"_out"`
#'
#' @return
#' @export
#'
#' @examples
#' \dontrun{
#' concord(data_in = equal_pm$data_A,
#' pm = equal_pm$pm_BA,
#' from_code = std_A,
#' to_code = std_B,
#' m_weights = weight,
#' values_from = c(A_100),
#' .suffix = "_out")
#' }
#'
concord <- function(data_in, pm, from_code, to_code, m_weights, values_from, .suffix=NULL){
## defuse arugments
str.to <- rlang::as_string(rlang::enexpr(to_code))
str.from <- rlang::as_string(rlang::enexpr(from_code))
## check conditions
pm |>
check_weights(code_in = {{from_code}},
code_out = {{to_code}},
weights = {{m_weights}})
subset_in <- tryCatch(
data_in |>
dplyr::select({{from_code}}, {{values_from}}),
error = function(cnd) {
cli::cli_abort(
"{.var from_code} or {.var values_from} could not be found in {.var data_in}",
class = "vals_not_found")
}
)
subset_in |>
check_missing()
check_coverage(subset_in, pm, str.from)
## apply transformation
# -- create suffix --
out_suffix <- .suffix %||% paste0("_", str.to)
join_by <- str.from
data_out <- use_panel_map(.data = subset_in, .map = pm,
.from = {{from_code}}, .to = {{to_code}}, .weights = {{m_weights}},
.vals = {{values_from}}, .suffix = out_suffix,
.by = join_by)
return(data_out)
}Internal function without checks
#' Apply panel_map to data without checks
#'
#' A wrapper around a `{dplyr}` pipeline that takes a panel_map,
#' joins it with data, and transforms selected variables in that data according to
#' instructions in the panel map. Any groups in `data_in` are preserved.
#'
#' @param .data a Data Frame assumed to meet Source Data conditions
#' @param .map a Data Frame assumed to meet Panel Map conditions
#'
#' @return The output has the following properties:
#' * Groups are taken from `data_in`
#'
use_panel_map <- function(.data, .map, .from, .to, .weights, .vals,
.suffix, .by){
# subset data for transformation
data_in <- .data %>%
dplyr::select({{.from}}, {{.vals}})
# merge map and data // use default by= argument
map_join_data <- dplyr::right_join(x = data_in,
y = .map,
by = .by)
# apply transformation
data_out <- map_join_data %>%
dplyr::mutate(dplyr::across({{ .vals }}, ~ .x * {{ .weights }})) %>%
dplyr::group_by({{ .to }}, .add = TRUE) %>%
dplyr::summarise(dplyr::across({{ .vals }}, ~ sum(.x)), .groups = "drop_last")
# rename
data_out <- data_out %>%
dplyr::rename_with(., ~ paste0(.x, .suffix), .cols = {{.vals}})
return(data_out)
}4.3.1.4 Tests
Define some test data:
equal_pm$data_B <-
dplyr::right_join(x = equal_pm$data_A,
y = equal_pm$pm_BA,
by = "std_A") |>
dplyr::mutate(A_100 = A_100 * weight) |>
dplyr::group_by(std_B, .add = TRUE) |>
dplyr::summarise(dplyr::across(c(A_100), ~ sum(.x), .names = "{.col}_out"),
.groups = "drop_last")Do the tests:
testthat::test_that(
"use_panel_map() works as expected", {
testthat::expect_identical(
use_panel_map(.data = equal_pm$data_A,
.map = equal_pm$pm_BA,
.from = std_A,
.to = std_B,
.weights = weight,
.vals = c(A_100),
.suffix = "_out",
.by = "std_A"),
equal_pm$data_B
)
}
)## Test passed 🎉testthat::test_that(
"concord() raises expected errors",
{
## columns not in data_in
testthat::expect_error(concord(data_in = equal_pm$data_A,
pm = equal_pm$pm_BA,
from_code = std_A,
to_code = std_B,
m_weights = weight,
values_from = c(missing_col1, missing_col2)
),
class="vals_not_found")
## missing values in data_in
testthat::expect_error(concord(equal_pm$bad_data, equal_pm$pm_BA, std_A, std_B, weight,
values_from = c(A_100)
),
class="vals_na"
)
## invalid weights are flagged
testthat::expect_error(concord(equal_pm$data_A, equal_pm$bad_weights, std_A, std_B, weight,
values_from = c(A_100)
),
class="invalid_weights"
)
}
)## Test passed 😀testthat::test_that(
"concord() works as expected",
{
testthat::expect_identical(concord(data_in = equal_pm$data_A,
pm = equal_pm$pm_BA,
from_code = std_A,
to_code = std_B,
m_weights = weight,
values_from = c(A_100),
.suffix = "_out"),
equal_pm$data_B
)
}
)## Test passed 🎉